Jeśli używasz Claude Code do czegokolwiek poza chatem — sub-agenci, długie sesje, zautomatyzowane pipeline’y — to pewnie patrzyłaś/patrzyłeś na swój usage dashboard i zadałaś sobie pytanie: która konfiguracja zrobi to samo, tylko taniej?
Tym razem postanowiłam to sprawdzić u siebie. Sześć kontrolowanych konfiguracji na tym samym tickecie inżynierskim. Dwa modele, trzy kształty promptu. To samo środowisko, to samo zadanie, te same kryteria akceptacji.
Wynik:
Sonnet 4.6 + 4-punktowy “addendum efektywnościowy” wygrał z każdą inną konfiguracją — pod kątem output tokenów, turnów, cache reads i czasu wall-clock. Bez utraty jakości. Ten sam model bez tego promptu zużył 27% turnów i 24% output tokenów więcej. Opus 4.7 spalił 1.5–2× więcej tokenów niż Sonnet na tym samym zadaniu, nie poprawiając AC.
Niżej: setup, liczby, prompt który właśnie wstawiam do produkcji, i parę rzeczy które mnie zaskoczyły.
Skąd się to wzięło
Buduję Drift — prywatny agent runner, któremu mogę oddelegować pracę. Pomysł jest egoistyczny i prosty: wystawiam ticket z telefonu, kiedy jestem na spacerze z psem, agenty go odbierają, robią robotę, a po powrocie do biurka mam gotowy diff do code review.
Każdy ticket kosztuje tokeny. Sonnet vs Opus, z tuningiem promptu albo bez — rachunek skacze 2–3× na tym samym zadaniu. Zanim wyskaluję Drift na większe projekty klienckie, chciałam mieć twarde liczby, która konfiguracja jest najtańsza przy tej samej jakości.
Stąd benchmark A–F.
Co mierzyłam (i dlaczego akurat te modele)
Dwa modele × trzy kształty promptu = sześć konfiguracji:
| Konfig | Model | Kształt promptu |
|---|---|---|
| A | Sonnet 4.6 | standardowy (baseline) |
| B | Sonnet 4.6 | grep-first + max 15 wywołań narzędzi |
| C | Opus 4.7 | standardowy |
| D | Opus 4.7 | grep-first + max 15 wywołań narzędzi |
| E | Sonnet 4.6 | parallel tool batching |
| F | Opus 4.7 | parallel tool batching |
Dlaczego te dwa modele? Sonnet 4.6 to koń roboczy — szybki, tani, w większości przypadków wystarczająco dobry do kodu. Opus 4.7 jest pozycjonowany pod trudniejsze rozumowanie, ale kosztuje ~5× więcej za token. Cały sens testu: sprawdzić czy Opus realnie zarabia na swoją cenę w rutynowej pracy inżynierskiej, czy może Sonnet plus mądrzejszy prompt pokrywa to samo taniej.
Trzy kształty promptu:
- Baseline — standardowy system prompt, którego moje agenty już używają, bez dodatków.
- Addendum efektywnościowy — 4-punktowy blok mówiący agentowi: grepuj zanim otworzysz plik, czytaj tylko to czego naprawdę potrzebujesz, twardy limit 15 wywołań narzędzi. (Pełna treść niżej.)
- Parallel batching — inny dodatek, zachęcający model do wywoływania niezależnych narzędzi w jednym turnie zamiast sekwencyjnie.
Co mierzyłam:
turns— ile roundtripów model → narzędzie → model agent zrobiłoutput tokens— to, za co płacę po stronie odpowiedzicache read— kontekst, który model dociągał z cache (proxy na puchnięcie kontekstu)time— wall-clock durationAC— kryteria akceptacji zaliczone, na 7
Zadanie było realistycznym ticketem inżynierskim: dodać per-type limity równoległości do 3000-liniowego workera w Pythonie. Siedem mechanicznie weryfikowalnych AC — stałe, sygnatury funkcji, stringi w logach, syntax check przez ast.parse. Nietrywialne (agent musi się odnaleźć w dużym pliku i przerobić główną pętlę), ale to nie jest też architektura od zera. Sensowny proxy na typowy ticket implementacyjny.
Runda 1 — trzy konfiguracje na rozgrzewkę
Zaczęłam od trzech konfiguracji, żeby zweryfikować że cały setup w ogóle ma sens, zanim odpalę pełną macierz:
| Konfig | Model | Prompt | AC | Turns | Out tok | Cache read |
|---|---|---|---|---|---|---|
| A | Sonnet | standardowy | 7/7 | 24 | 3 744 | 864 K |
| B | Sonnet | grep-first + max 15 wywołań narzędzi | 7/7 | 19 | 3 276 | 640 K |
| C | Opus | standardowy | 7/7 | 33 | 7 590 | 1 584 K |
Dwa wnioski z pierwszej rundy:
- Prompt efektywnościowy działa. B zużył 21% mniej turnów i 13% mniej output tokenów niż A — ten sam model, to samo zadanie, ta sama jakość końcowa.
- Opus jest drogi — i wcale nie lepszy. To samo 7/7 AC, ale 2× output tokenów i 2.5× cache reads vs Sonnet baseline. Na dobrze zdefiniowanym tickecie z weryfikowalnymi AC Opus nie ma żadnej przewagi.
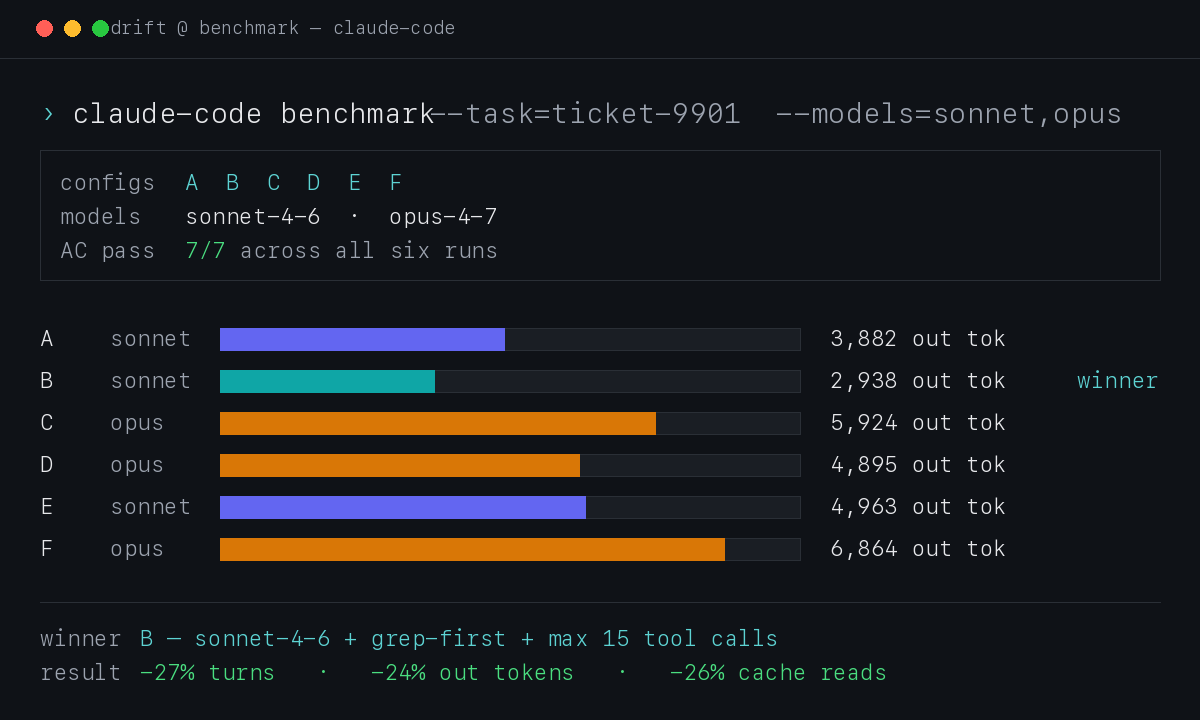
Runda 2 — pełna macierz A–F
Każda konfiguracja na świeżym git worktree z tego samego commita. Świeży kontekst, zero cross-contamination:
| Konfig | Model | Prompt | AC | Turns | Tools | Batched | Out tok | Cache read | Czas |
|---|---|---|---|---|---|---|---|---|---|
| A | Sonnet | standardowy | 7/7 | 22 | 13 | 0 | 3 882 | 769 K | 55s |
| B | Sonnet | grep-first + max 15 wywołań narzędzi | 7/7 | 16 | 11 | 0 | 2 938 | 566 K | 50s |
| C | Opus | standardowy | 7/7 | 29 | 16 | 0 | 5 924 | 1 427 K | 80s |
| D | Opus | grep-first + max 15 wywołań narzędzi | 7/7 | 17 | 10 | 0 | 4 895 | 793 K | 60s |
| E | Sonnet | parallel batching | 7/7 | 34 | 20 | 0 | 4 963 | 1 204 K | 80s |
| F | Opus | parallel batching | 7/7 | 27 | 18 | 0 | 6 864 | 1 270 K | 80s |
Co mówią liczby:
- B wygrywa po całości. Najniższy wynik na każdej metryce kosztowej. 27% mniej turnów i 24% mniej output tokenów niż baseline Sonnet, AC bez zmian.
- Prompt efektywnościowy pomaga też Opusowi. C → D: 29 → 17 turnów (−41%), 5 924 → 4 895 output tokenów (−17%). Oba modele słuchają instrukcji.
- Parallel batching odwrotnie zadziałał na Sonnecie. E było gorsze niż baseline A — 34 turny vs 22, 4 963 vs 3 882 output tokenów. Instrukcja wyzwoliła dodatkową narrację planistyczną, ale faktycznych batchowanych wywołań nie wygenerowała.
- Zero batchowanych turnów we wszystkich sześciu konfiguracjach. Kolumna “Batched” to same zera. O batchowaniu decyduje model, prompt tego nie wymusi.
Opus słucha promptu — i wciąż przegrywa z Sonnetem na każdej metryce.
Środowisko testowe — dla zainteresowanych replikacją
Czysty benchmark to taki, gdzie nic z runa nie przecieka do realnych systemów. Trzy elementy załatwiły tę robotę:
Git worktrees, jeden per konfiguracja. Każdy agent dostał własną kopię roboczą repo, gałąź z tego samego commita:
git worktree add /tmp/exp/wt-A HEAD
git worktree add /tmp/exp/wt-B HEAD
# ... C, D, E, FTo samo źródło, sześć odizolowanych workspace’ów. Agent mógł grepować, czytać, edytować, młotkować kod — nic z tego nigdy nie dotknęło produkcyjnego checkoutu, nic nie wpadało do merge’a. Po każdym runie worktree był resetowany do HEAD, żeby kolejny agent zaczął z czystym stanem.
Fake HTTP server w miejscu prawdziwego API. Agenci Drifta normalnie wołają REST API, żeby oznaczyć ticket jako rozpoczęty, zalogować postęp, zamknąć. Na potrzeby eksperymentu zastąpiłam to minimalnym serwerem, który akceptuje każde wywołanie i ignoruje payload:
GET /api/tickets/9901 → zwraca fake ticket
POST /api/tickets/9901/events → 200 OK (drops payload)
PATCH /api/tickets/9901 → 200 OK (drops payload)Brak produkcyjnej bazy, brak triggerowania realnych workerów, brak ryzyka że eksperyment niechcący promotuje się do rzeczywistości. Agent myśli że robi robotę; system łyka wynik bez efektu.
Czemu nie odpalić tego po prostu na produkcji? Z dwóch powodów:
- Powtarzalność. Produkcyjne tickety mają historię — komentarze, wcześniejsze próby, realne diffy. Trudno zrobić sześć runów naprawdę identycznych.
- Bezpieczeństwo. Sześć nienadzorowanych agentów na tym samym tickecie ścigałoby się ze sobą, dublowało zapisy, korumpowało stan. Worktrees + fake server zrobiły z runów równoległych coś bezpiecznego i identycznego.
Prompty (do skopiowania)
Addendum efektywnościowy (konfiguracje B i D — zwycięzca):
## INSTRUKCJA EFEKTYWNOŚCI
Pracuj liniowo i minimalnie:
1. ZAWSZE zrób grep/search zanim otworzysz plik —
nie czytaj pliku "żeby zobaczyć co tam jest"
2. Czytaj tylko te fragmenty których potrzebujesz
(użyj offset+limit w Read)
3. Nie exploruj dookoła — jeśli AC mówi
"dodaj funkcję przy linii 302", idź tam bezpośrednio
4. Limit: 15 wywołań narzędzi łącznie.
Po 15 — zakończ z tym co masz.Cztery punkty. Tyle. −27% turnów, −24% output tokenów, AC bez zmian.
Addendum parallel batching (konfiguracje E i F — to które się odbiło):
## INSTRUKCJA PARALLEL TOOL USE
Gdy masz kilka niezależnych operacji do wykonania —
wywołaj je wszystkie w jednym turnie, nie sekwencyjnie.
Dotyczy to zarówno czytania różnych fragmentów tego
samego pliku (Read offset=0, Read offset=300,
Read offset=3100 równocześnie), jak i niezależnych
grepów czy sprawdzeń w różnych plikach.Model rozumie intencję (widać że narratywuje w outputcie co zrobi równolegle), ale stream wywołań we wszystkich sześciu runach zawiera dokładnie zero batchowanych tool callów. Promptowe wymuszenie batchowania wygląda na non-feature w trybie -p.
Parę rzeczy które mnie zaskoczyły
-
Najtańsza konfiguracja jest też najszybsza. B skończył 5 sekund szybciej niż A. Mniej eksplorowania → mniej wall-clock, nie tylko mniej tokenów.
-
Opus + prompt efektywnościowy (D) wciąż wychodzi drożej niż baseline Sonnet (A). D spalił 4 895 output tokenów; A spalił 3 882. Jeśli płacisz za Opusa i tuningujesz prompt, wciąż wydajesz więcej niż na nietuningowanym Sonnecie — przy tych samych AC.
-
Wszystkie sześć runów zaliczyło 7/7 AC. Ważny kontekst: mierzyłam “najtańsze przy tej samej jakości”, nie “najlepsze jakościowo”. Na fuzzy zadaniach bez weryfikowalnych AC Opus może wciąż wyjść na prowadzenie. Na dobrze zdefiniowanych ticketach inżynierskich — nie.
-
Parallel batching to realna feature w Claude Code — tylko że decyduje o tym model, nie prompt. CLI nie ma na to flagi. API ma
tool_choice, ale subskrybenci Claude Max nie dostają tego przez CLI. Czyli na razie: dzieje się gdy model uzna że powinno, a dopisanie “proszę batchuj” do promptu produkuje tylko więcej tekstu o batchowaniu. -
Dwie rundy, dwóch zwycięzców — tych samych. Benchmark odpaliłam dwa razy dla sanity check. Inne dni, inne worktrees, to samo zadanie, ten sam wynik: B wygrywa, podobnymi marginesami. Wniosek nie jest jednorazową fluktuacją.
Co z tym robię
Drift wjeżdża z addendum efektywnościowym w każdym tickecie typu impl. 4-punktowy blok siedzi w konfiguracji workera i jest doklejany do system promptu przed każdym runem agenta. Ten sam model, to samo zadanie, około 25% mniej kosztu per ticket. Biorę.
Przy większych projektach — gdzie agent czyta po wielu plikach i pisze po wielu modułach — odpalę benchmark ponownie, zanim założę że ten sam prompt wciąż wygrywa. Aktualne stwierdzenie jest wąskie, ale solidne: na dobrze zdefiniowanym tickecie implementacyjnym w znanym kodzie, Sonnet plus grep-first wygrywa z każdą inną konfiguracją Claude Code którą sprawdziłam.
Jeśli używasz Claude Code w jakimkolwiek pipelinie i masz weryfikowalny test case, odpal sobie taki benchmark na własnym zadaniu, zanim wybierzesz model. Domyślne ustawienia nie są najtańsze. Najdroższy model nie jest najlepszy. A 4-punktowy addendum do promptu potrafi ściąć ćwiartkę rachunku za tokeny zanim w ogóle ruszysz model.